Классификация по Байесу
Свой классификатор Байеса, кажется, не написал только ленивый. На удивление простая модель с допущениями, от которых у любого математика начинают шевелиться уши, на практике работает с потрясающей точностью. Определение спама, классификация текстов по жанрам, товарных предложений по категориям или даже поиск модели ноутбука в наборе строк — со всеми этими задачами успешно справляются классификаторы Байеса.
Расскажу на примере как работает самый простой классификатор Байеса. Допустим, мы хотим классифицировать книги на основе их краткого описания. У нас есть исходная база знаний в виде дерева категорий и набора уже классифицированных книг. На основе этих данных мы можем посчитать для каждого слова, которое встречается в описаниях, вероятность его принадлежности к определенной категории по следующей формуле:

W — слово, C — категорияcount(C, W) — количество слов W в описаниях книг из категории Ccount(C, books) — количество книг в категории CНормализация по числу книг нужна, чтобы не терять в общей массе маленькие категории с большой встречаемостью слова. Например, в категории
C1 "Тракторы в поэзии 20-го века" есть 30 книг, в описаниях которых слово "трактор" встречается 60 раз. А в категории C2 "Спецтехника", соответственно, 6000 книг и 1000 раз встречается слово "трактор". Таким образом, без нормализации:Что однозначно относит слово "трактор" в категориюP(C1, "трактор") = 60 / (1000 + 60) ~ 0.056P(C2, "трактор") = 1000 / (1000 + 60) ~ 0.944
С2. Если использовать нормализацию, мы получаем:P(C1, "трактор") ~ 0.925
P(C2, "трактор") ~ 0.075Посчитав вероятности для каждого слова из нашей базы знаний, мы готовы классифицировать книги. Вероятность принадлежности книги
 Здесь
Здесь
Все! Классификатор Байеса готов работе. В следующий раз я расскажу о некоторых методиках обучения на некачественных данных и о двух интересных способах применения полученного классификатора.
book к категории C равна: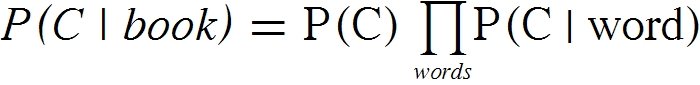 Здесь
Здесь P(C) это априорная вероятность встречаемости категории C, которая равна отношению числа книг в C к общему числу книг. С помощью этого множителя мы учитываем, что книги о "Спецтехнике" встречаются гораздо чаще, чем "Тракторы в поэзии". Необходимо отметить, что P(C|word) может быть нулем, если слово не встретилось в категории ни одного раза, в таком случае обычно подставляют в формулу какое-либо маленькое значение.Все! Классификатор Байеса готов работе. В следующий раз я расскажу о некоторых методиках обучения на некачественных данных и о двух интересных способах применения полученного классификатора.

7 комментариев:
Мне кажется Вы ошиблись в формуле для полной вероятности, там должна быть сумма
Нет, все правильно.
Сумма будет если прологарифмировать, что часто используется, особенно на больших документах (чтобы избежать underflow, когда вероятность становится такой маленькой, что не может быть представлена double)
Простите, а как будет выглядеть тогда формула?
Все, разобрался.
Вместо произведения вероятностей подставить сумму их логарифмов.
Есть еще такой вопрос будет ли корректно работать алгоритм для книг разной длины? Ведь с увеличением размера книги (документа) вычисляемая вероятность будет все больше понижаться.
Если документы очень длинные обычно используют k самых вероятных слов из них. Нужное число, как обычно, подбирается экспериментально.
В последней формуле "P(C|book) = P(C)П..." умножение производится без учёта частоты слова в классифицируемой книге? Т.е. например в книге есть 1000 слов "машина" и одно слово "цветок", и мы пытаемся определить принадлежность книги к категориям например "Цветоводство" и "Машиностроение". Должны ли мы P(C|машина) учесть только один раз или 1000 (т.е. учесть каждое вхождение слова в книгу)?
Забавно - получается, суммарная вероятность принадлежности книги ко всем имеющимся категориям - гораздо меньше 1.0? Или это математически уже не полная вероятность?
Отправить комментарий