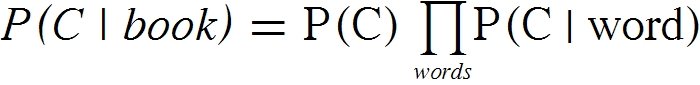Не делайте лишнего
В реализации алгоритма k-средних основная операция — вычисление расстояния между двумя векторами Увидев в профайлере, что на метод
Для хранения разреженного вектора заводится два массива: массив индексов и массив значений.
Как можно складывать такие вектора? Самый очевидный способ (который и реализован в классе
В getIndex() ищется место индекса в массиве и, при необходимости, создается место под новый. Его алгоритмическая сложность
Конечно же, сразу хочется реализовать сложение векторов с помощью слияния двух массивов за
Как же нам улучшить производительность вычисления нормы разности векторов? Ответ прост, нам же совершенно не нужно вычислять разность векторов, это лишняя операция. Надо лишь на каждом шаге алгоритма слияния массивов вычислять очередное слагаемое нормы. Так мы избавляемся от затратной операции записи в массив и лишней операции чтения. После такой оптимизации скорость работы выросла в 3-4 раза.
||a - c||. Очевидный способ это сделать, используя библиотеку MTJnew SparseVector(vector).add(-1, centroid).norm(Vector.Norm.Two)add() приходится около 90% всех вычислений, возникает естественное желание попытаться его ускорить. Как работает этот метод? Для этого нам надо понять, как вообще устроен SparseVector.Для хранения разреженного вектора заводится два массива: массив индексов и массив значений.
Индексы отсортированы по возрастанию. При чтении элемента вектора бинарным поиском ищется его индекс, потом выбирается соответствующий индексу элемент из массива значений. Запись элемента происходит следующим образом: если по этому индексу уже есть элемент, то он просто перезаписывается, если же элемента нет, то оба массива раздвигаются в нужном месте (при необходимости увеличивается их длина) и сохраняется новый индекс и значение для него.
index
12
15
86
87
90
125
234
235
value
1.42
1.2
0.01
0.43
1.23
2.41
2.55
0.143
Как можно складывать такие вектора? Самый очевидный способ (который и реализован в классе
SparseVector) выглядит так:public void add(int index, double value) {
check(index);
int i = getIndex(index);
data[i] += value;
}
В getIndex() ищется место индекса в массиве и, при необходимости, создается место под новый. Его алгоритмическая сложность
O(log(n)), где n длина вектора, к которому мы добавляем. При этом нельзя забывать о достаточно большой константе связанной с раздвижением массива. Соответственно, общая сложность получается O(m log(n)), где m длина вектора, который мы добавляем.Конечно же, сразу хочется реализовать сложение векторов с помощью слияния двух массивов за
O(m + n). Вот только для некоторых m и n такое слияние будет даже медленнее чем первый способ. Например, для n = 100 и m = 20 (самые обычные значения во многих задачах).Как же нам улучшить производительность вычисления нормы разности векторов? Ответ прост, нам же совершенно не нужно вычислять разность векторов, это лишняя операция. Надо лишь на каждом шаге алгоритма слияния массивов вычислять очередное слагаемое нормы. Так мы избавляемся от затратной операции записи в массив и лишней операции чтения. После такой оптимизации скорость работы выросла в 3-4 раза.
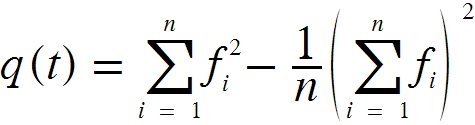
 Здесь,
Здесь,